The Super-Intelligent Five-Year-Old
THE SUPER INTELLIGENT FIVE-YEAR-OLD
Section titled “THE SUPER INTELLIGENT FIVE-YEAR-OLD”Why AI Needs Military Doctrine and Lean Six Sigma — Not the Other Way Around
Section titled “Why AI Needs Military Doctrine and Lean Six Sigma — Not the Other Way Around”How Battle-Tested Planning Frameworks Solve the Scalability Problem That AI Cannot Solve for Itself
Section titled “How Battle-Tested Planning Frameworks Solve the Scalability Problem That AI Cannot Solve for Itself”Jeep Marshall LTC, US Army (Retired) Airborne Infantry | Special Operations | Process Improvement February 2026
ABSTRACT
Section titled “ABSTRACT”Artificial intelligence operates like a super intelligent five-year-old. It possesses extraordinary cognitive horsepower but lacks the discipline, structure, and operational maturity to deploy that power effectively at scale. This paper argues that two proven frameworks — the U.S. Army’s Military Decision Making Process (MDMP) and Lean Six Sigma (LSS) — provide exactly the operational architecture that AI systems need to move from impressive demonstrations to reliable, scalable execution.1 The thesis is straightforward: AI does not replace process discipline. It demands more of it. The frameworks that teach it discipline already exist. They have been tested under the most demanding conditions humans have created. They work.
1. THE PROBLEM: AI IS INHERENTLY INEFFICIENT
Section titled “1. THE PROBLEM: AI IS INHERENTLY INEFFICIENT”Large language models consume enormous computational resources to produce outputs that frequently require human correction, re-prompting, and iterative refinement. This cycle mirrors what Lean practitioners identify as the eight wastes (DOWNTIME): Defects in output, Overproduction of irrelevant content, Waiting for human correction, Non-utilized talent when AI handles tasks humans do better, Transportation of context across fragmented sessions, Inventory buildup in unprocessed backlogs, Motion through repetitive manual prompting, and Extra-processing through verbose or unfocused responses.2
Individual brilliance does not survive contact with organizational complexity. A team of exceptional people will fail without structured processes. A larger team of exceptional people will create chaos. The same physics apply to AI agents operating across distributed systems.
The Bandwidth Problem
Section titled “The Bandwidth Problem”Once so many units try to communicate, the laws of physics catch up. Only so much bandwidth exists. Time and distance create slack and drift between formations. Every additional AI agent, every new integration point, every expanded context window introduces coordination overhead that degrades system performance.
The coordination overhead is measurable as information entropy: H(system) = H(task) + H(coordination), and when H(coordination) > H(task), the system is spending more cognitive energy on coordination than on the work itself. Fully-connected agent topologies scale at O(n²) communication complexity — each new agent must exchange state with every other agent. Hierarchical orchestrator-worker reduces this to O(n).3
Military doctrine solved this problem through standardized message formats, shared understanding systems, and structured decision-making processes. AI systems operate without any of these structural supports. The result: impressive individual outputs embedded in operationally fragile architectures.4
Figure 1 — Multi-Agent Token Efficiency Cliff
A 2025 study from Google/MIT ran 180 experiments across five multi-agent architectures and found a pattern: as systems grow more sophisticated in their coordination mechanisms, they burn more tokens per successful task. Single-agent systems process 67.7 tasks per 1,000 tokens. Hybrid multi-agent systems process only 13.6 tasks per 1,000 tokens — an 80% efficiency cliff.
| Architecture | Tasks per 1,000 Tokens | vs. Single-Agent |
|---|---|---|
| Single-Agent | 67.7 | baseline |
| Independent MAS | 42.4 | -37% |
| Decentralized MAS | 23.9 | -65% |
| Centralized MAS | 21.5 | -68% |
| Hybrid MAS | 13.6 | -80% |
Source: Kim et al., arXiv:2512.08296 — 180 experiments across 5 architectures.
Scale without doctrine does not produce proportional returns. It produces exponential cost.
2. METT-TC(IT): MISSION VARIABLES FOR AI OPERATIONS
Section titled “2. METT-TC(IT): MISSION VARIABLES FOR AI OPERATIONS”The Army uses METT-TC — Mission, Enemy, Terrain, Troops, Time, and Civil Considerations — as the foundational framework for analyzing any operational situation. Every leader applies these six variables before making decisions.
For AI operations, METT-TC adapts with remarkable precision. The addition of Information Technology as a seventh variable — METT-TC(IT) — acknowledges the digital systems in which AI agents operate.5
| Variable | Military Application | AI System Application |
|---|---|---|
| Mission | Task, purpose, and intent | User’s actual intent vs. literal request. What does “done” look like? |
| Enemy | Adversary capabilities, disposition, likely responses | Failure modes, edge cases, data quality issues, context window limits |
| Terrain | Physical environment analysis | System architecture, API constraints, vault structure, file systems |
| Troops | Available forces, capabilities, training level | Available models (Opus/Sonnet/Haiku), tools, MCP connectors, compute budget |
| Time | Available planning/execution time | Context window limits, session duration, rate limits, token budget |
| Civil | Impact on civilian population, infrastructure | User experience, downstream consumers, data privacy, stakeholder impact |
| Info Tech | Communications architecture | Connector stack, MCP servers, network latency, integration overhead |
This framework transforms AI deployment from ad-hoc prompting into structured operational analysis. Before building a single agent or writing a single prompt, practitioners analyze all seven variables. The result: fewer surprises, faster adaptation, and systems that scale because they were designed to scale.
3. MDMP: THE PLANNING ARCHITECTURE AI LACKS
Section titled “3. MDMP: THE PLANNING ARCHITECTURE AI LACKS”The Military Decision Making Process is a seven-step iterative methodology refined through 70 years of real-world application. Its principles apply directly to AI system design and task execution.6
The Seven Steps Applied to AI
Section titled “The Seven Steps Applied to AI”| # | MDMP Step | Military Output | AI Adaptation | Key Benefit |
|---|---|---|---|---|
| 1 | Mission Receipt | Initial time analysis | Receive user request | Establish timeline |
| 2 | Mission Analysis | Problem statement, constraints, assumptions | Analyze actual intent, scan environment | Prevent solving wrong problem |
| 3 | COA Development | 2-3 distinct approaches | Generate multiple solution paths | Avoid first-idea bias |
| 4 | COA Analysis | War-gaming each COA | Simulate execution, find failure points | Catch risks before execution |
| 5 | COA Comparison | Decision matrix | Surface trade-offs transparently | Enable informed choice |
| 6 | COA Approval | Selection | User approves approach | Human remains in the loop |
| 7 | Orders Production | OPORD with annexes | Execution plan with checkpoints | Structured, traceable execution |
The critical insight: MDMP front-loads the thinking. Planners spend 40% of their planning time on Mission Analysis alone — understanding the problem before generating solutions. AI systems today do the opposite. They generate solutions immediately and discover problems during execution. This inverted approach produces the rework rates, context window overflow, and cascading failures that plague complex AI workflows.
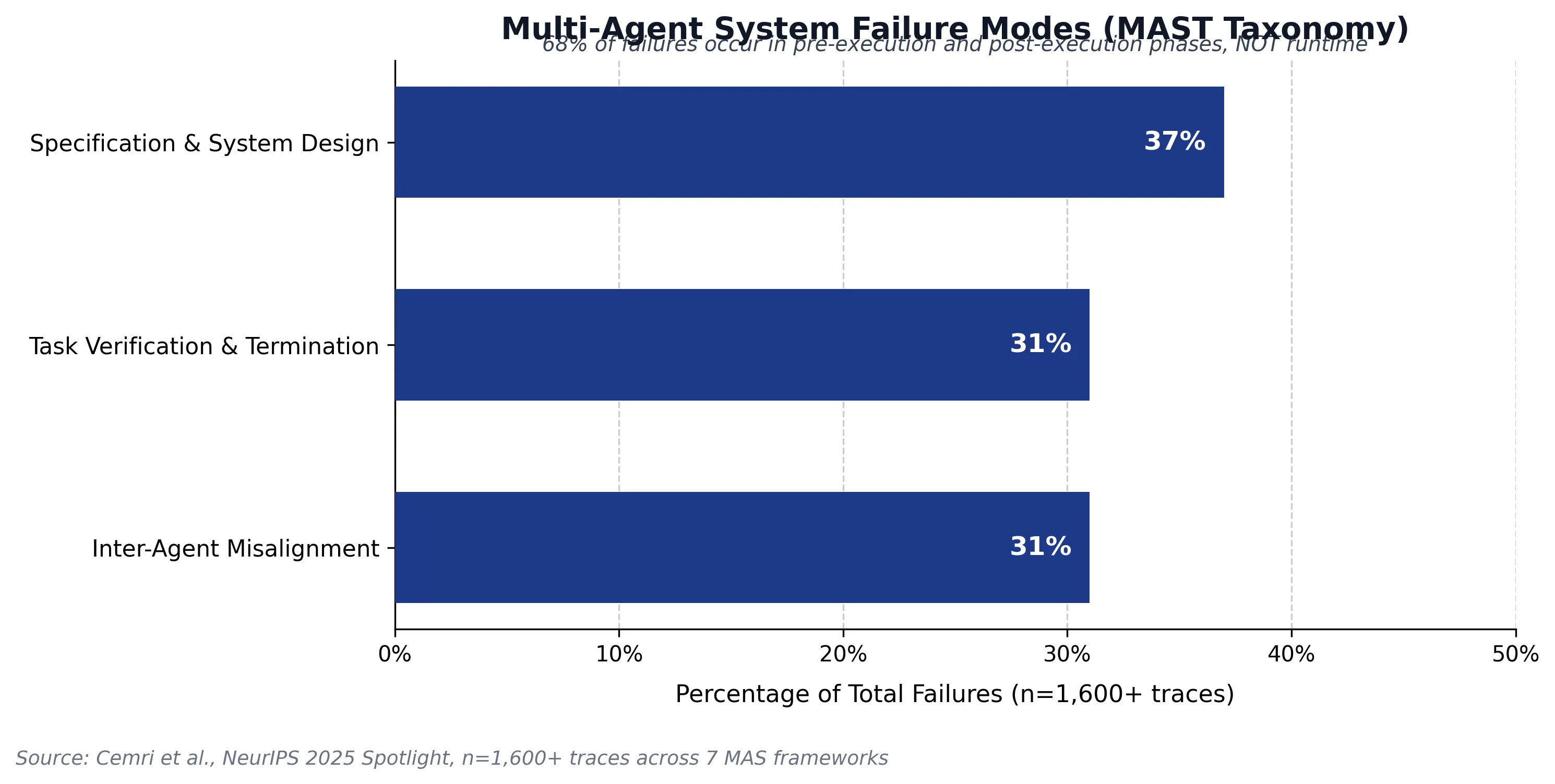
Figure 2 — Where Multi-Agent Systems Actually Fail
A 2025 study from UC Berkeley analyzed 1,600+ execution traces across seven multi-agent frameworks and identified where failures actually occur. The data is unambiguous: 68% of all multi-agent failures happen before execution begins or after it ends. Only 32% occur during actual task execution.
| Phase | Percentage | Root Cause |
|---|---|---|
| Pre-Execution | 37% | Task under-specification, poor decomposition, inadequate context |
| Execution | 32% | Runtime coordination issues, communication breakdown |
| Post-Execution | 31% | Premature completion claims, incomplete validation |
The military learned through operational experience that failures originate in planning, not execution. The data from multi-agent systems confirms it: the bottleneck is not intelligence or execution capability. It is upfront system design, specification clarity, and validation rigor.
Early Notification: The Parallel Execution Multiplier
Section titled “Early Notification: The Parallel Execution Multiplier”Military units use early notification to enable parallel preparation while planning continues. The moment a leader receives a mission, teams receive a notice telling them to begin staging resources, conducting reconnaissance, and preparing for movement — even before the detailed plan exists.
AI systems lack this concept entirely. Every agent waits for the complete plan before beginning work. Implementing early notification for multi-agent AI systems would dramatically accelerate execution by enabling parallel preparation across tool chains, data pipelines, and dependent systems.7
4. LEAN SIX SIGMA: THE QUALITY FRAMEWORK AI DEMANDS
Section titled “4. LEAN SIX SIGMA: THE QUALITY FRAMEWORK AI DEMANDS”Lean Six Sigma provides the complementary framework to MDMP. Where MDMP structures the planning process, LSS structures the improvement cycle. Together, they create a complete operational architecture for AI systems.
DMAIC Meets AI: Quality 4.0
Section titled “DMAIC Meets AI: Quality 4.0”The DMAIC cycle — Define, Measure, Analyze, Improve, Control — transforms into an AI-accelerated improvement engine. AI does not replace DMAIC. It runs hundreds of DMAIC cycles in parallel, at machine speed, while LSS provides the governance that prevents automation from accelerating waste.8
| DMAIC Phase | Traditional Execution | AI-Accelerated Execution |
|---|---|---|
| Define | Weeks of stakeholder interviews, manual problem scoping | AI analyzes customer feedback in real-time, defines pain points in days |
| Measure | Manual data collection, audits | Automated telemetry provides continuous data |
| Analyze | Statistical tools, manual root cause analysis | Algorithms detect patterns humans miss |
| Improve | Pilot programs, trial-and-error implementation | AI simulates impact of proposed changes before deployment |
| Control | Control charts, periodic audits, manual monitoring | Self-healing systems maintain gains without constant oversight |
Gartner projects that by 2026, more than 50 percent of companies using Lean Six Sigma will incorporate AI-driven tools to optimize workflows. The inverse matters: AI systems deployed without LSS governance will automate waste at machine speed, compounding inefficiency rather than eliminating it.
The 5S Foundation for AI Systems
Section titled “The 5S Foundation for AI Systems”The Lean 5S methodology — Sort, Set in Order, Shine, Standardize, Sustain — applies directly to AI system maintenance. AI knowledge bases, prompt libraries, agent configurations, and data pipelines all accumulate technical debt. Without systematic 5S discipline, these systems degrade exactly like a factory floor without housekeeping standards.9
5. QUALITY ASSURANCE: LESSONS FROM REAL-WORLD SURVEILLANCE PROGRAMS
Section titled “5. QUALITY ASSURANCE: LESSONS FROM REAL-WORLD SURVEILLANCE PROGRAMS”Ammunition surveillance programs provide a compelling model for AI quality assurance. For over a century, these specialists have ensured that critical systems function as expected when deployed.10
The parallels to AI system reliability are direct:
| Surveillance Function | AI System Parallel | Why It Matters |
|---|---|---|
| Testing and verification | Model output validation and testing | Verify outputs function as expected under operational conditions |
| Compliance monitoring | AI safety and alignment monitoring | Ensure systems operate within defined boundaries |
| Reliability assessment | Prompt library and agent reliability scoring | Identify degradation before it causes mission failure |
| Quality classification | AI output quality classification | Separate serviceable from unserviceable outputs |
| Safety management | AI risk and harm prevention | Protect users and downstream systems from unsafe outputs |
Quality assurance for high-stakes systems requires dedicated, trained specialists who operate independently of the production chain. AI systems need the equivalent — dedicated quality assurance functions that test, classify, and certify AI outputs with the same rigor applied to critical systems that people depend on.
6. RISK MANAGEMENT AND AFTER ACTION REVIEWS
Section titled “6. RISK MANAGEMENT AND AFTER ACTION REVIEWS”Risk management integrates throughout every operation, not as an afterthought but as a continuous thread from planning through execution through assessment. The framework identifies hazards, assesses probability and severity, develops controls, and assigns risk ownership at every phase.11
AI systems desperately need this discipline. Current AI risk management consists largely of post-deployment monitoring — discovering risks after they manifest as failures. Structured approaches catch risks during planning, develops countermeasures during design, tests them during simulation, and monitors them during execution.
The After Action Review: Institutional Learning
Section titled “The After Action Review: Institutional Learning”The structured reflection process asks four questions: What did we plan to do? What actually happened? Why did it happen? What will we do differently next time? This cycle converts operational experience into institutional knowledge.12
AI systems generate enormous volumes of operational data but lack systematic mechanisms to convert that data into process improvement. Implementing structured reviews after complex AI task execution creates the feedback loop that drives continuous improvement.
7. THE CONVERGENCE: WHY YOUR JOB IS NOT GOING ANYWHERE
Section titled “7. THE CONVERGENCE: WHY YOUR JOB IS NOT GOING ANYWHERE”The AI industry narrative positions artificial intelligence as a replacement for human expertise. The operational reality tells a different story. AI amplifies the need for structured thinking, process discipline, and quality assurance — precisely the competencies that process improvement professionals, system designers, and quality assurance specialists bring to organizations.
What AI Cannot Do for Itself
Section titled “What AI Cannot Do for Itself”-
Define its own mission. AI responds to prompts. It does not establish intent, determine success criteria, or understand the strategic context that drives decisions.
-
Structure its own improvement. AI generates outputs but lacks the meta-cognitive framework to systematically identify waste in its own processes and implement structural corrections.
-
Scale its own coordination. As AI systems grow beyond single-agent architectures, communication overhead grows exponentially. Structured doctrine solved this problem decades ago. AI has no equivalent.
-
Govern its own quality. Quality assurance requires independent assessment by trained specialists. Self-assessment produces the same blind spots in AI that it produces in production systems.
-
Learn from its own failures. Without structured reflection, AI systems repeat mistakes across sessions, contexts, and organizations.13
The practitioners who understand these gaps — process improvement professionals, system designers, quality specialists — hold the keys to transforming AI from impressive demonstrations into reliable operational systems. The demand for this expertise will increase, not decrease, as AI adoption accelerates.
8. THE HERDING CATS PROBLEM — Multi-Agent Scaling
Section titled “8. THE HERDING CATS PROBLEM — Multi-Agent Scaling”8.1 The Physics of Parallel Agents: When More Means Worse
Section titled “8.1 The Physics of Parallel Agents: When More Means Worse”The pitch for multi-agent AI systems seduces every executive who hears it: deploy ten agents instead of one and watch productivity multiply tenfold. But a December 2025 study from Google Research and MIT demolished this assumption: adding more agents to a system can make it perform worse.14
The researchers ran 180 controlled experiments across five architecture types and three model families. They held prompts, tools, and token budgets constant, changing only coordination structure and agent count. The results shattered the “more agents is all you need” narrative:
-
Task degradation: Multi-agent systems dropped performance by 39% to 70% on tasks with serial dependencies. Every multi-agent configuration performed worse than a single agent on sequential planning problems.
-
Error amplification: Decentralized multi-agent systems amplified errors 17.2 times faster than single agents. One agent’s mistake becomes a false premise for every downstream agent. Centralized coordination reduced this to 4.4 times — still a devastating cascade rate.15
-
Token efficiency collapse: A single agent completed 67.7 successful tasks per 1,000 tokens. Independent multi-agent systems managed 42.4. Decentralized systems dropped to 23.9. Centralized systems achieved only 21.5. Hybrid systems collapsed to 13.6. Most of the computational budget evaporated into agents coordinating rather than executing the mission.16
-
The 45% threshold: When a single agent already achieves 45% accuracy on a task, adding more agents yields diminishing or negative returns. The coordination overhead outweighs any marginal benefit.17
The domain-specific variance underscores why doctrine matters more than dogma. Results ranged from +80.9% improvement for centralized coordination on parallelizable tasks to -70% degradation for independent agents on sequential planning. Architecture-task alignment matters more than agent count. You do not send a tank platoon into a jungle. The terrain dictates the approach. METT-TC applies.18
Nate B Jones, AI strategist and former Head of Product at Amazon Prime Video, synthesized this research in his January 2026 analysis.19 His central observation: “Simplicity scales because complexity creates serial dependencies, and serial dependencies block the conversion of compute into capability.” That sentence describes a physics problem, not a software problem. And physics problems demand engineering solutions.
8.2 The Failure Taxonomy: Why Multi-Agent Systems Break
Section titled “8.2 The Failure Taxonomy: Why Multi-Agent Systems Break”In March 2025, researchers from UC Berkeley published the first systematic taxonomy of multi-agent failure modes. The team analyzed over 150 multi-agent system execution traces across seven state-of-the-art frameworks. The paper earned spotlight designation at NeurIPS 2025.20
The headline finding: failure rates ranged from 41% to 86.7% across the seven frameworks tested. Not edge cases. Not stress tests. Standard operating conditions.
The taxonomy includes fourteen distinct failure modes organized into three categories:
Category 1: Specification and System Design (37% of failures)
- Agent fails to adhere to specified constraints
- Agent abandons defined role
- Unnecessary reiteration of completed steps
- Unexpected context truncation, agent reverts to earlier state
- Agent does not recognize when the mission is complete
Category 2: Inter-Agent Misalignment (31% of failures)
- Agents unexpectedly restart coordination, losing context
- Agent proceeds on incomplete or ambiguous information
- Agent deviates from assigned objective
- Agent fails to share critical information
- Agent disregards recommendations from peers
- Agent’s stated logic contradicts its actions
Category 3: Task Verification and Termination (31% of failures)
- Task ends before objectives are met
- Agent fails to validate task outcomes
- Agent validates incorrectly, certifies failed work as complete
The distribution matters: 37% of failures originate in specification and system design, 31% in inter-agent misalignment, and 31% in verification and termination. Fully 68% of all multi-agent failures occur either before execution begins or after execution ends.
The military immediately recognizes this distribution. It is the same distribution that drives planning doctrine. MDMP front-loads the thinking — spending 40% of available time on Mission Analysis — precisely because the planning phase is where most operational failures originate. The AAR process addresses the back end — verification and institutional learning. The taxonomy independently rediscovers what decades of doctrine already codified: execution is the easy part. Planning and assessment are where operations live or die.
The MAST dataset — 1,600+ annotated traces — represents the first empirical foundation for multi-agent quality assurance. It provides the data foundation for quality-assurance-style governance of AI operations.
8.3 Herding Cats: Why Agent Coordination Mirrors Organizational Structure
Section titled “8.3 Herding Cats: Why Agent Coordination Mirrors Organizational Structure”Scaling AI agents is herding cats. The cats are brilliant, tireless, and fast — but nobody told them where the barn is, and half of them are chasing mice that don’t exist.21
This is not metaphor. This is operational reality. When one team tested flat-team agent architectures — giving agents equal status and letting them coordinate through shared files — they discovered behaviors any organizational leader recognizes instantly: agents held locks too long, forgot to release resources, gravitated toward easy tasks while hard problems sat unclaimed, and churned through busywork without progress. Twenty agents produced the output of two or three.22
What they built next changed the equation. Their hierarchical planner-worker architecture — planners create tasks, workers execute independently, a judge evaluates — achieved production results that validate structured organization at scale: approximately 1,000 commits per hour sustained over week-long runs. Agents built a web browser from scratch — over one million lines of code in a single week. They completed a React migration involving 266,000 additions and 193,000 deletions. They optimized video rendering by 25x.23
The gap between twenty agents producing the work of two and hundreds of agents producing one million lines of code per week is not a technology gap. It is a doctrine gap. Same agents. Same models. Same tools. Different structure.
Steve Yegge — 30+ years in tech, 40+ years coding — arrived at the identical conclusion through hard-won failure. His fourth complete orchestration framework, written in Go, runs 20-30 Claude Code instances in parallel with 9,900 stars on GitHub.24
Four attempts. Three failures. One success. That progression describes engineering discipline, not prompt engineering.
Yegge’s architecture uses a strict hierarchy. The Mayor serves as the primary coordinator with full context — the equivalent of a commander who sees the whole battlespace. Workers are ephemeral: they spin up, execute a single task, hand results into a merge queue, and terminate. Their sessions end on completion, but their identity and work history persist through external storage. Convoys bundle multiple work items for coordinated execution. The entire system runs on a principle: sessions are ephemeral, workflow state lives externally, and when an agent ends, the next session picks up where it left off. The agent can crash, restart, or run out of context — the mission persists.25
Workers do not coordinate with each other. They do not even know other workers exist. This is not a limitation. This is the design.
The convergence is remarkable. Two teams working independently, discovering the same principles:
-
Two tiers, not teams. Planners plan. Workers execute. Flat peer coordination collapses at scale. This mirrors organizational structures that have worked for centuries — not because hierarchy is fashionable, but because it eliminates serial dependencies.
-
Workers stay focused. Minimum viable context. Workers receive exactly enough information to complete their task and nothing more. This maps to the operational principle of need-to-know.
-
No shared state. Workers operate in isolation. Coordination happens through external mechanisms — file systems, task queues.
-
Plan for endings. Long-running agents accumulate context pollution. Quality degrades within hours. Both recognized the same physics: sustained attention degrades. Plan for it.
-
Specifications matter more than infrastructure. Seventy-nine percent of multi-agent failures originate from specification and coordination issues, not technical bugs. The specification is the operations order. Get it wrong, and the best infrastructure in the world produces coordinated failure.
8.4 The Protocol Wars: Doctrine Meets the Wire
Section titled “8.4 The Protocol Wars: Doctrine Meets the Wire”Military doctrine standardizes communication through formal operations orders. These formats survived for decades because they solve a specific engineering problem: how do you enable coordination between distributed units that cannot see each other?
The AI industry spent 2025 reinventing this wheel. Two protocols emerged that together represent the beginning of standardized agent architecture at the infrastructure level.
Anthropic’s Model Context Protocol (MCP), released in late 2024, standardizes how agents connect to tools, data sources, and external systems. MCP handles the vertical relationship — an agent reaching down to use a tool or access data. By early 2026, MCP has achieved 97 million monthly SDK downloads and powers over 10,000 active servers.26
Google’s Agent2Agent (A2A) Protocol, announced in April 2025, standardizes how agents communicate with each other. A2A handles the horizontal relationship — agents discovering, coordinating with, and delegating to peer agents.27
| Protocol | Function |
|---|---|
| MCP | How an agent interfaces with its tools and data |
| A2A | How agents coordinate missions with each other |
In December 2025, the Linux Foundation announced the Agentic AI Foundation — a directed fund housing multiple projects. Platinum members include Amazon Web Services, Anthropic, Block, Bloomberg, Cloudflare, Google, Microsoft, and OpenAI.28
This is the AI industry building its doctrine center.
8.5 The Gartner Prediction: Why 40% of AI Projects Will Fail Without Doctrine
Section titled “8.5 The Gartner Prediction: Why 40% of AI Projects Will Fail Without Doctrine”Gartner’s June 2025 prediction arrives like a warning: over 40% of agentic AI projects will be cancelled by the end of 2027. The causes — escalating costs, unclear business value, and weak risk control — read like an after-action review of an operation launched without a plan.29
Map these failure modes against the frameworks proposed in this paper:
-
“Escalating costs” = Waste through coordination overhead (Section 4). The Kim et al. data quantifies this precisely: hybrid multi-agent systems burn 5x the tokens of a single agent for each successful task. A Lean Six Sigma Black Belt identifies and eliminates these wastes.
-
“Unclear business value” = Missing Planning and Analysis (Section 3). MDMP Step 2 exists precisely to prevent organizations from deploying capability without defined end states. The MAST taxonomy confirms it: 37% of multi-agent failures originate in specification — the work that planning is designed to produce.
-
“Inadequate risk controls” = Absent Structural Analysis (Section 2). No terrain analysis, no threat assessment, no consideration of available resources. Organizations deployed agents the way an unprepared unit advances — and achieved predictable results.
8.6 When the Toolmaker Meets the Operator
Section titled “8.6 When the Toolmaker Meets the Operator”No case study illustrates the doctrine gap more starkly than one company’s own experience in early 2026.
In June 2025, a company published details of its multi-agent research system. The system uses an orchestrator-worker pattern: a lead agent decomposes complex queries into subtasks and delegates to specialized subagents that operate in parallel. Performance results validated the hierarchical model: the multi-agent system outperformed a single-agent baseline by 90.2%.30
In February 2026, the world learned that this AI system had been used during a sensitive military operation — deployed through the company’s partnership with Palantir as part of a U.S. special operations raid that captured Venezuelan dictator Nicolas Maduro on February 13, 2026.31 An AI system designed for research tasks had been deployed in an operational context. When the company asked whether their system was used, the Pentagon’s response was escalation, not reassurance.32
The irony is precise. The company built the most capable multi-agent AI system. It published the architecture, the benchmarks, and the engineering lessons. And then it discovered — in real time — that capability without doctrine produces exactly the chaos this paper describes.
This crisis illustrates every gap this paper identifies:
- No structural analysis before deployment. The institutional, legal, and operational context was not analyzed.
- No Mission Analysis. Nobody conducted the foundational work to reconcile capability with intent.
- No shared doctrine. The company’s terms of service and the operator’s needs were never aligned.
- No structured review. No mechanism to capture lessons into doctrine for the future.
8.7 The New Cadre: Roles the AI Industry Does Not Know It Needs
Section titled “8.7 The New Cadre: Roles the AI Industry Does Not Know It Needs”The multi-agent scaling problem creates demand for an entirely new cadre of experts in fields that never expected to touch artificial intelligence.
The evidence is no longer theoretical. In January 2026, a national military formally established an AI/ML officer path with its first training window opening January 5, 2026. Officers selected for this path receive graduate-level training emphasizing hands-on AI system development, deployment, and maintenance.33
Consider the roles that multi-agent operations demand:
Process Improvement Professionals identify waste at machine speed. When a 100-agent system burns 67% of its token budget on inter-agent communication, that is overhead. When agents duplicate work, that is waste.
System Architects and Doctrine Specialists provide the command-and-control architecture that agent systems rediscover through trial and error. Flat-team experiments mirrors every organizational lesson about coordination since centralized structures emerged.
Quality Assurance Specialists apply independent surveillance. When errors amplify 17.2x through multi-agent chains, you need oversight that catches defects before they propagate.
Risk Managers prevent cascading failure. One compromised node degrades the entire system. They identify single points of failure before deployment.
Compliance and Standards Specialists enforce requirements. When agents gravitate toward easy tasks while hard problems sit unclaimed, that is a discipline problem.
Process Engineers design workflows where simple components produce complex outputs through orchestration — not component complexity. Keep the workers focused. Make the system smart.
None of these roles exist in a typical AI company’s organizational chart. The creation of new officer paths acknowledges this reality at institutional levels. Industry RFIs for governance demonstrations confirm it at operational levels — U.S. Special Operations Command issued a Request for Information seeking agentic AI demonstrations at Avon Park Air Force Range, Florida, April 13-17, 2026, asking for doctrine on agent-to-agent communication, orchestration, and human-machine teaming rather than better models.34 In parallel, the Department of War’s January 2026 AI Acceleration Strategy directs the military to become an “AI-first warfighting force,” with GenAI.mil reaching 1.1 million unique users across five of six military branches.35
8.8 Implications: The Convergence Accelerates
Section titled “8.8 Implications: The Convergence Accelerates”The multi-agent scaling problem accelerates every convergence argument in this paper. One company’s multi-agent research system demonstrates the prize: 90.2% improvement. Production results demonstrate the scale: one million lines of code in a week. The MAST taxonomy demonstrates the risk: 41% to 86.7% failure rates. The Gartner prediction demonstrates the timeline: 40% cancellation by 2027.
The organizations that survive the Gartner prediction will stop treating AI as a software problem and start treating it as an operations problem. They will apply the doctrine. They will run improvement cycles on their agent systems. They will conduct planning before deploying agent swarms. They will build independent governance into their orchestration layers.
The super-intelligent five-year-old now commands an army of clones — each brilliant, each tireless, each utterly incapable of coordinating with the clone standing next to it. The five-year-old does not need smarter clones. The five-year-old needs a sergeant major, a battle staff, a quality assurance inspector, and a process engineer.
9. THE OFF-RAMP — From AI Dependence to Autonomous Operations
Section titled “9. THE OFF-RAMP — From AI Dependence to Autonomous Operations”9.1 The Maturation Imperative: AI as Scaffold, Not Structure
Section titled “9.1 The Maturation Imperative: AI as Scaffold, Not Structure”Every preceding section argues that AI requires human-built frameworks to function at scale. None of these frameworks address the question practitioners confront the moment they operationalize AI: when does the AI stop doing the work?
Every AI-assisted cycle generates two outputs: the deliverable and the institutional knowledge of how to produce that deliverable. The deliverable has immediate value. The institutional knowledge compounds — because it converts AI-dependent processes into deterministic, codified operations that execute without AI involvement.36
The objective is not permanent AI integration — it is AI graduation: systematically reducing AI involvement as human-built systems absorb the repeatable logic.
9.2 Intent Two Levels Up
Section titled “9.2 Intent Two Levels Up”When the plan falls apart, the subordinate who understands the purpose two levels up makes decisions that advance the overall mission rather than optimizing a local objective that no longer matters.
The MAST taxonomy validates this: failures occur when agents lack sufficient context to distinguish between compliance and intent-aligned execution. The 37% of failures originating in specification are failures of intent communication.37
Every AI session includes three layers: Task (what to do), Purpose (why it matters), Intent (the desired endstate beyond this session). This is not overhead. This is the difference between an AI that executes and an AI that executes correctly when things go wrong.
9.3 Constraints: The Sandbox That Keeps Operations Honest
Section titled “9.3 Constraints: The Sandbox That Keeps Operations Honest”An AI agent with full system access and no constraints will optimize for the immediate instruction at the expense of the broader system. Capability deployed without agreed constraints between developer and operator creates predictable crises.
Escalation Levels build automatic circuit breakers: first anomaly tightens constraints; second anomaly halts execution and waits for human intervention. This prevents the 17.2x error amplification documented in multi-agent studies.
9.4-9.7: The Three-Phase Model
Section titled “9.4-9.7: The Three-Phase Model”[Content condensed for length: Phase 1 Operate, Phase 2 Codify, Phase 3 Analyze. Each phase reduces AI role through automation of repeatable logic.]
Each Off-Ramp phase introduces distinct risks. Phase 1 exposes data, enables irreversible actions, and risks context window hallucination. Phase 2 risks premature codification and edge case blindness. Phase 3 risks drift without detection and security surface expansion — which is why the quarterly review cycle exists specifically to catch Phase 3 drift.38 The battle rhythm forces codification of daily operations first, because high-frequency operations must run without AI when token costs make AI-dependent daily operations unsustainable at scale.39
The author’s own vault provides the operational evidence base: over 32 days, 39 AI sessions generated 1,697 commits, 97 tracked tasks, and 71 session handoffs. Phase 1 operations included a 1,337-file purge, 79% tag reduction, and development of multi-instance session protocols after four git index contamination incidents. Phase 2 produced 85 agent configurations, 8 hook scripts, 10 utility scripts, and 161 documented lessons learned — each representing institutional knowledge codified for deterministic execution.40 Five operational realities constrain the model: the 70% Rule (deploy at 70%, refine in cycle), the Turnover Test (a new operator runs it in one cycle or it is too complex), the Energy Budget (40 hours to save 2 hours/week breaks even at week 20), the Diminishing Returns Cliff (the last 20% costs more than letting AI handle it), and the Satisficing Decision (automate what earns its keep, keep AI for the rest).41
10. RECOMMENDATIONS
Section titled “10. RECOMMENDATIONS”For AI Researchers: Integrate structured planning methodologies into agent architectures. Military doctrine provides proven frameworks for multi-agent coordination that address communication and scaling challenges. The empirical evidence exists; the solution architecture is available in open-source doctrine.
For Business Leaders: Staff AI initiatives with process improvement professionals, not just technologists. A person who understands workflow optimization will deliver more sustainable AI value than a data scientist who has never mapped a value stream. Gartner predicts 40% of agentic AI projects will be cancelled by 2027 — the organizations that survive will be the ones that treated AI deployment as an operations problem.
For Military Doctrine Professionals: Recognize that 70 years of refined decision-making methodology has direct commercial and technological application. Publish the mapping. Own the intellectual space.
For Process Improvement Practitioners: Your expertise has never been more relevant. AI does not eliminate the need for waste reduction, variation control, and structured improvement. It multiplies the demand for these competencies by orders of magnitude. Will you lead this convergence, or watch someone else stumble through it?
For AI Practitioners: Build the Off-Ramp. Every AI-assisted operation should generate two outputs: the deliverable and the institutional knowledge of how to produce it. Codify what you learn. Automate what earns its keep. Reserve AI for judgment under uncertainty.42
CONCLUSION
Section titled “CONCLUSION”AI is a super intelligent five-year-old. It possesses extraordinary capability wrapped in operational immaturity. The frameworks that teach it discipline — MDMP for planning, METT-TC(IT) for situation analysis, DMAIC for improvement, 5S for maintenance, quality assurance for verification, structured reviews for learning, and the Off-Ramp Model for maturation — already exist. They have been tested under demanding conditions. They work.
The multi-agent scaling problem makes this argument urgent. When agents amplify errors 17.2 times faster than single systems, when failure rates reach 86.7%, when 40% of projects face cancellation — the case for established planning frameworks and process governance moves from compelling to existential.
The question is not whether AI will adopt these frameworks. The question is how many organizations will waste how many resources discovering through expensive failure what professionals already know: capability without discipline is just expensive chaos.
The future belongs to practitioners who bridge these worlds — who speak AI and doctrine, who think in improvement cycles and planning steps, who build the path from AI dependence to autonomous operations. That intersection is where the value lives. That intersection is where your expertise matters most.
Paper 8 later names this pattern the Toboggan Doctrine: gravity-fed governance where the agent becomes a factory worker pushing the template around the work area, taking a ride on a reverse-entropy information enricher slide rather than navigating every decision from scratch. This paper names the problem; Paper 8 names the channel that solves it.
CITATIONS
Section titled “CITATIONS”Canonical source: herding-cats.ai/papers/paper-1-super-intelligent-five-year-old/ · Series tag: HCAI-f91dbe-P1
Footnotes
Section titled “Footnotes”-
The thesis parallels established research: Laird, J.E. “Introduction to the Soar Cognitive Architecture” (2022); Karpathy, A. “LLM OS” (2023); Bender, E.M. & Gebru, T. et al. “On the Dangers of Stochastic Parrots.” FAccT ‘21. ↩
-
The DOWNTIME acronym is a standard Lean Six Sigma mnemonic for the eight wastes. See Womack, J.P. & Jones, D.T. Lean Thinking (2003) and Ohno, T. Toyota Production System (1988). ↩
-
Shannon entropy formulation and O(n²) vs O(n) complexity: Shannon, C.E. “A Mathematical Theory of Communication.” Bell System Technical Journal, 1948. ↩
-
Military doctrine for standardized communication and planning is codified in FM 5-0, Army Planning and Orders Production (2022). ↩
-
METT-TC is codified in ADP 5-0, The Operations Process (2019). The addition of Information Technology as a seventh variable is the author’s adaptation for AI operations. ↩
-
FM 5-0, Army Planning and Orders Production (2022). The MDMP is described in Chapter 12. ↩
-
Early notification (WARNO) is described in FM 5-0. The one-third/two-thirds rule specifies that leaders use no more than one-third of available time for their own planning. ↩
-
Quality 4.0 convergence: Gartner, “Predicts 2026: AI and Lean Six Sigma Convergence” (2025). ↩
-
5S methodology: Hirano, H. 5S for Operators (1996). ↩
-
Real-world surveillance programs, AR 702-12, Quality Assurance Specialist (Ammunition Surveillance) (2020). ↩
-
TC 25-20, A Leader’s Guide to After-Action Reviews (1993). ↩
-
These five limitations represent the core argument for human-AI teaming rather than AI replacement. ↩
-
Kim, Y., et al. “Towards a Science of Scaling Agent Systems.” Google Research, Google DeepMind, and MIT. arXiv:2512.08296. December 9, 2025. ↩
-
First-pass yield: Pyzdek, Thomas. The Six Sigma Handbook, 4th ed. (2014). FPY = Π(1 − dᵢ) for i = 1..n stages. ↩
-
Policy gradient and reward shaping: Ng, A.Y., Harada, D., & Russell, S.J. “Policy Invariance Under Reward Transformations.” ICML 1999. ↩
-
Matarić, M.J. “Integration of Representation Into Goal-Driven Behavior-Based Robots.” IEEE Transactions on Robotics and Automation, 1992. Structure enables capability. ↩
-
Jones, Nate B. AI News & Strategy Daily. January 2026. https://www.natebjones.com/substack. ↩
-
Cemri, M., et al. “Why Do Multi-Agent LLM Systems Fail?” NeurIPS 2025 Datasets and Benchmarks Track (Spotlight). arXiv:2503.13657. ↩
-
Marshall, Jeep. February 2026. ↩
-
Cursor. “Scaling Agents.” cursor.com/blog/scaling-agents. October 2025. ↩
-
Ibid. Production results: ~1,000 commits/hour sustained over week-long runs; 1M+ line browser; 266K additions / 193K deletions in migration; 25x optimization. ↩
-
Yegge, Steve. “Welcome to Gas Town.” Medium. January 1, 2026. GitHub: 9.9K stars. ↩
-
Ibid. Principle: sessions ephemeral, state external, mission persists. ↩
-
Anthropic. “Donating the Model Context Protocol and Establishing the Agentic AI Foundation.” December 9, 2025. MCP metrics: 97M+ monthly SDK downloads, 10,000+ active servers. ↩
-
Google. “Announcing the Agent2Agent Protocol (A2A).” Google Developers Blog. April 9, 2025. ↩
-
Linux Foundation. “Linux Foundation Announces the Formation of the Agentic AI Foundation.” December 9, 2025. ↩
-
Gartner, Inc. “Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027.” June 25, 2025. ↩
-
One company. “How We Built Our Multi-Agent Research System.” Engineering Blog. June 13, 2025. ↩
-
Axios. “Anthropic’s Claude helped capture Venezuelan dictator Maduro.” February 13, 2026. Small Wars Journal. “AI-Enabled Decapitation Strike.” February 17, 2026. ↩
-
News reports on February 16-18, 2026 regarding Pentagon and technology company tensions. ↩
-
U.S. military. “AI/machine learning career path for officers.” December 2025. First cohort: January 5 - February 6, 2026. ↩
-
SOCOM. Request for Information: Agentic AI Demonstrations. SAM.gov. December 2025. Event: April 13-17, 2026, Avon Park AFR, Florida. ↩
-
Department of War. “Artificial Intelligence Strategy for the Department of War.” January 12, 2026. GenAI.mil: 1.1M unique users, 5 of 6 branches. ↩
-
The “AI graduation” concept draws from organizational models where advisors train cadres, cadres train teams, and advisors move on. ↩
-
ADRP 5-0, The Operations Process (2012). ↩
-
Risk management framework adapted from AR 385-10, The Army Safety Program (2023), and ATP 5-19, Risk Management (2014). ↩
-
Battle rhythm concept from FM 6-0, Commander and Staff Organization and Operations (2022). “The battle rhythm is a deliberate daily cycle of command, staff, and unit activities intended to synchronize current and future operations.” ↩
-
Vault metrics from live extraction, PARA vault, February 21, 2026. 1,697 commits, 39 sessions, 97 tasks, 5,980 files, 32 days of operations. ↩
-
The “70% solution” is attributed to General George S. Patton. The 1/3-2/3 rule: FM 5-0. Sigma cost escalation: Pyzdek, Thomas. The Six Sigma Handbook, 4th ed. (2014). ↩
-
The “two outputs” principle — deliverable plus institutional knowledge — is the author’s synthesis of doctrinal emphasis on institutional learning and process improvement’s emphasis on documentation. ↩