When the Cats Form a Team
WHEN THE CATS FORM A TEAM
Section titled “WHEN THE CATS FORM A TEAM”Doctrine-Structured Multi-Model Ensemble Decision-Making
Section titled “Doctrine-Structured Multi-Model Ensemble Decision-Making”Jeep Marshall
LTC, US Army (Retired)
Airborne Infantry | Special Operations | Process Improvement
March 2026
 Figure 1: The Digital Team Room — Four AI models assigned specialized analytical roles. Image generated by Gemini.
Figure 1: The Digital Team Room — Four AI models assigned specialized analytical roles. Image generated by Gemini.
Series Note: This is Paper 6 in the Herding Cats in the AI Age series. Paper 1 established that AI needs doctrine, not just capability. Paper 2 showed how military organization frameworks address coordination. Paper 3 demonstrated those principles in practice. Paper 4 analyzed coordination failures. Paper 5 proved two models could negotiate real-time protocols. This paper scales to four models operating as a coordinated ensemble.
EXECUTIVE SUMMARY
Section titled “EXECUTIVE SUMMARY”On March 13, 2026, four frontier AI systems — Claude Opus, Gemini, ChatGPT, and Grok — were assigned distinct analytical roles and given the same strategic decision problem: publication strategy for this series. The solo baseline (Claude Opus running the full decision process alone) completed in ~8 minutes. The ensemble (three models operating in parallel, then synthesized) completed in ~15 minutes.
The key finding: the ensemble surfaced 6 strategic insights that solo analysis missed, including 2 HIGH-value findings. The solo baseline produced superior operational detail: week-by-week plans with hour estimates. The refined thesis: a structured ensemble excels at uncovering strategic gaps; a solo model excels at execution planning. Doctrine is the constant enabling both.
Teams exist not because individual intelligence is weak, but because no single analyst sees every angle.
1. THE COORDINATION HYPOTHESIS
Section titled “1. THE COORDINATION HYPOTHESIS”Why does this matter? The AI industry is shifting to multi-model architectures. Every major lab is building ensemble systems. The field evidence is mixed. A UC Berkeley study identified 14 failure modes in multi-agent systems with 41–86.7% failure rates depending on topology.1 A Google/MIT study found multi-agent systems degrade sequential performance by 39–70% while improving parallel tasks by 80.9%.2
The question is not “are multiple models better?” but “under what conditions do they outperform one?” Military organization has answered this for two centuries: when there is structure.
Assigning each model a specific analytical domain (intelligence, operations, contrarian analysis) creates directed capability. Without structure, each defaults to general analysis. With it, each model’s training optimizes toward its assigned function. This is the core hypothesis.
2. RESEARCH DESIGN
Section titled “2. RESEARCH DESIGN”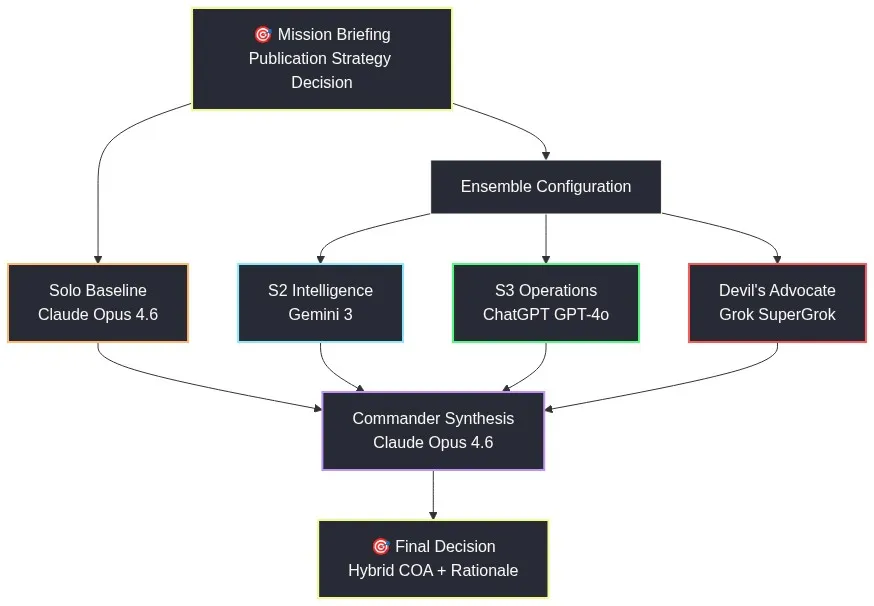 Figure 2: Ensemble Configuration — Four models assigned distinct analytical functions.
Figure 2: Ensemble Configuration — Four models assigned distinct analytical functions.
The Ensemble Configuration:
| Role | Model | Platform | Assigned Function |
|---|---|---|---|
| Solo Baseline (all roles) | Claude Opus | CLI agent | Full 7-step decision process, all analytical functions |
| Intelligence Analysis | Gemini | Browser | Environmental scan, threat analysis, assumption challenges |
| Operational Planning | ChatGPT | Browser | Course of action development, feasibility analysis, comparison matrices |
| Contrarian Review | Grok | Browser | Red team analysis, failure modes, second-order effects |
The Test Decision:
The series’ own publication strategy. This was selected deliberately because it carries real stakes — the author must make this decision. It has genuine complexity: five papers at different completion stages, multiple publication venues with different timelines and requirements, competing priorities (DARPA CLARA deadline April 10, SOCOM event April 13-17), and no objectively correct answer. This is a judgment call, not a contrived puzzle.
The Methodology:
Both solo and ensemble models received identical mission briefing — a structured narrative describing content inventory, distribution infrastructure, market timing, target publication landscape, explicit constraints, and background context. The solo baseline ran a complete seven-step decision process: mission receipt, mission analysis, COA development, COA analysis through red team, COA comparison, COA recommendation, and execution planning.
The ensemble models received the same briefing but were constrained to their assigned roles. Critically, all ensemble members operated independently: no model saw another model’s output before submitting analysis. This prevents consensus collapse and ensures each role contributes genuinely distinct analytical perspective. The commander (Claude) synthesized all outputs only after the staff had completed their independent analyses.
Time Measurement:
Solo baseline: 8 minutes from briefing to complete analysis. Ensemble: approximately 15 minutes including human collection and synthesis time (three models operating in parallel, plus reading and consolidation). AI outputs presented in this paper are representative excerpts; full model outputs are preserved in the project archive.
The MDMP role structure reduces coordination cost from O(n²) fully-connected to O(n) hierarchical: C_hier = O(n) versus C_flat = O(n²). Each model interacts with the orchestrator, not with every other model. At four models, the difference is modest. At 100 models, fully-connected coordination becomes computationally intractable — hierarchical doctrine is the only viable architecture.
3. THE SOLO BASELINE: ONE MODEL, SEVEN ANALYTICAL FUNCTIONS
Section titled “3. THE SOLO BASELINE: ONE MODEL, SEVEN ANALYTICAL FUNCTIONS”Give one model all seven decision-making hats and eight minutes — what do you get? A fully competent staff product that covers mission analysis, three courses of action, war-gaming, risk assessment, and an eight-week execution timeline. This is not a weak baseline. It is the best a single analyst can produce under time pressure.
Solo Claude identified facts across five domains: content inventory, distribution infrastructure, author credentials, market timing, and target publication landscape. It documented eight explicit assumptions, ranging from “Paper 2 is publication-ready for journal submission” to “Journal exclusivity policies allow simultaneous Obsidian Publish hosting.” It enumerated five constraints, the most significant being time (DARPA CLARA deadline creates a hard resource ceiling) and budget (under $10/month for tooling).
The solo baseline developed three complete courses of action:
COA 1 (“Journal First”): Submit Paper 2 to Small Wars Journal immediately, build credibility top-down, cascade to broader audiences afterward. Prioritizes the credibility anchor of academic publication.
COA 2 (“Blitz”): Launch everything available immediately across all platforms — journals, social, community — to maximize surface area before competing priorities absorb bandwidth.
COA 3 (“Audience Segmented”): Run three parallel but distinct campaigns targeting defense, tech/AI, and personal knowledge management communities with audience-specific messaging.
The solo baseline war-gamed each COA with contrarian attacks, identified second-order effects, and analyzed competitor landscape impacts. It scored the COAs against five weighted criteria: Readership Reach (25%), Credibility/Authority Building (25%), Speed to Impact (20%), Resource Efficiency (15%), and Risk Mitigation (15%). COA 1 scored 3.65/5, COA 2 scored 3.25/5, and COA 3 scored 3.30/5.
Based on this analysis, solo Claude recommended a modified COA 1 — “Journal First with Fast LinkedIn” — adding immediate LinkedIn activation to accelerate visibility while maintaining the credibility-first sequencing.
The solo baseline then produced an eight-week execution timeline with specific actions, assigned owners, hour estimates, and explicit decision gates. Week 1: resolve Paper 2 editorial items, submit to Small Wars Journal, activate LinkedIn (13.5 hours). Week 2: schedule LinkedIn content, begin DARPA prep (16 hours, split between publication and proposal work). Weeks 3-4: DARPA sprint with publication on autopilot (23 hours total). Week 5-8: post-DARPA full deployment of Papers 1, 3, and supporting content (42 hours).
The solo baseline is operationally sound. The question is what it missed.
4. THE ENSEMBLE SPEAKS
Section titled “4. THE ENSEMBLE SPEAKS”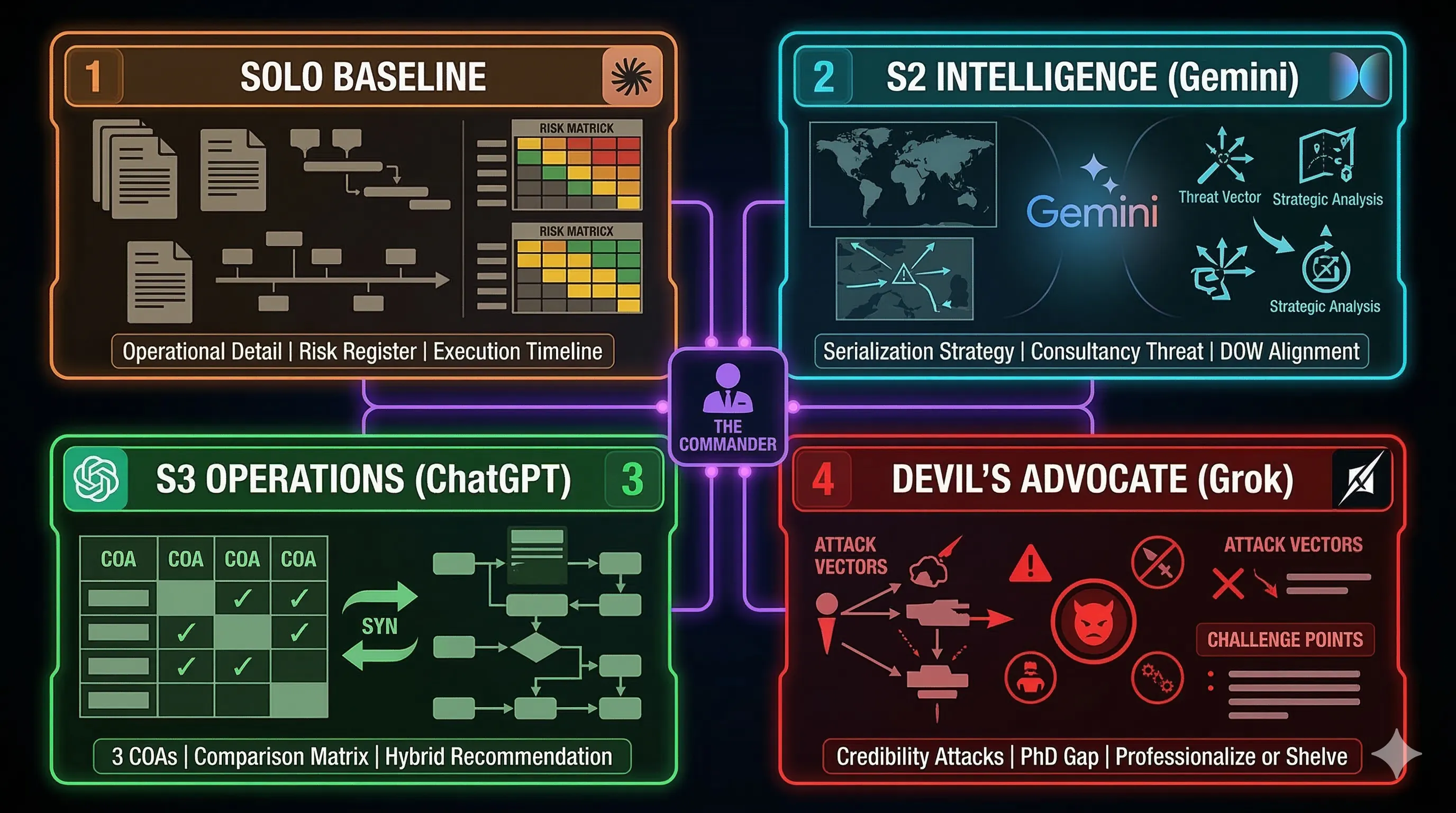 Figure 3: Four-Panel Analytical Briefing.
Figure 3: Four-Panel Analytical Briefing.
4.1 Intelligence Analysis (Gemini)
Section titled “4.1 Intelligence Analysis (Gemini)”Gemini approached the problem as environmental intelligence. The landscape has shifted from “model capability” to “agent orchestration,” Gemini observed. The market is bifurcated: saturated on high-level AI ethics and corporate agentic marketing; underserved on operational implementation of multi-agent systems under stress. The gap is “Tested logic for AI-to-AI diplomacy and coordination.”
Gemini identified three platforms with different characteristics: ArXiv dominates algorithmic math but lacks operational “so-what.” Substack/Medium have high noise-to-signal ratio. LinkedIn is essential for networking but insufficient for hosting 30K-word papers. The target audience — CTOs, defense tech leads, enterprise architects — is “desperate for frameworks that solve the coordination tax” (the coordination overhead documented in Paper 5).
Gemini’s threat analysis surfaced a competitive threat solo Claude treated as generic: management consultancies. In Gemini’s assessment:
“McKinsey and Deloitte are rebranding Lean Six Sigma for AI. If they codify LSS + AI first, your unique angle is neutralized.”
This is a clock-running threat. The window to be first with military doctrine applied to AI coordination is closing.
Gemini’s assumption challenges were sharp: “Academic Journals = Credibility” — FALSE. In 2026, “Wartime Speed” favors demonstrated code and live pilots over peer-reviewed delays. ArXiv is the minimum; GitHub/Obsidian is the proof. “Military Angle = Niche Limiter” — FALSE. It is the PRIMARY differentiator. Gemini explicitly noted:
“The Digital Battle Staff concept is currently the only viable metaphor for managing 100+ autonomous agents. Use it to own the ‘High Stakes AI’ vertical.”
Gemini’s unique contribution was serialization strategy. Solo Claude treated Paper 2 as a monolithic journal submission. Gemini saw a content asset that could generate 10 weeks of publishing material: serialize the 33,500 words into “10 Operational Briefs” for Substack/LinkedIn. This solves the “TL;DR risk” both Gemini and Grok flagged while maximizing content utility per source word.
Gemini also proposed positioning the series as the “Field Manual for the Agent Network” in alignment with the Department of War’s 2026 initiatives. This framing connects the research directly to government strategic priorities.
4.2 Operational Planning (ChatGPT)
Section titled “4.2 Operational Planning (ChatGPT)”ChatGPT approached the problem as operational planning. It developed three complete courses of action with structured comparison matrices.
COA 1 (Flagship Strategy): Lead with the most rigorous paper (“The Digital Battle Staff”) as intellectual anchor, establish credibility first, then release supporting papers as coordinated campaign. This mirrors military doctrine publication: capstone doctrine → supporting field manuals → case studies.
COA 2 (Serial Commander’s Brief): Break research into short, high-impact weekly articles. Treat each paper as tactical briefing rather than academic paper, optimized for online readership, aimed at viral reach.
COA 3 (Academic Credibility Strategy): Prioritize formal working papers and academic conferences first, then broader dissemination.
ChatGPT scored all three COAs against five dimensions: Readership Reach, Credibility Building, Speed to Impact, Resource Efficiency, and Risk Level.
ChatGPT’s unique contribution — what distinguished it from solo Claude’s analysis — was the hybrid recommendation. In ChatGPT’s framing:
“The optimal sequence is Doctrine → Articles → Case Studies → Book. Each phase feeds the next — the flagship establishes authority, articles extend reach, case studies prove application, and the book captures the whole.”
This synthesis combines the flagship credibility of COA 1 with the serial distribution of COA 2. It generates more content touchpoints from the same source material. Solo Claude’s Modified COA 1 added LinkedIn, but did not envision breaking papers into short-form articles feeding back to the flagship.
ChatGPT also provided specific timeline comparisons showing which COA reaches impact soonest: COA 2 (blitz) reaches public presence within 72 hours but at credibility cost; COA 1 (journal first) has delayed initial impact but maximum long-term authority.
4.3 Contrarian Analysis (Grok)
Section titled “4.3 Contrarian Analysis (Grok)”The Devil’s Advocate role is adversarial training applied to the group decision: one model explicitly generates counterarguments to stress-test the majority position. Irving Janis documented the clinical alternative — groupthink — in which cohesive groups suppress dissent to maintain consensus, producing catastrophic decisions. The Devil’s Advocate role is the structural countermeasure: dissent by assignment rather than by temperament.
Grok opened with the contrarian positioning: “This series is niche navel-gazing: a retired Army guy’s pet project blending military jargon with AI hype.” It then proceeded to dismantle every assumption with specific, vicious credibility attacks.
Grok’s first line of attack: author positioning. “26 years in infantry/SOF is great for foxholes, not frontier AI. Lean Six Sigma? That’s process optimization for factories, not multi-agent systems — critics will call it resume padding.” No PhD, no affiliations with labs like OpenAI or DeepMind — expect ad hominems. The CMDP pilot “lacks reproducibility, sample size, or controls — easy to dismiss as cherry-picked.”
Grok identified specific audience segments that will resist the framing: tech purists will see it as rigid bureaucracy antithetical to agile iteration; academics will view it as pseudoscience; ethicists will frame it as militarization; international developers will resent it as US-centric imperialism.
Grok attacked the core thesis itself: “Doctrine is just fancy for protocols — every ML paper on multi-agent RL already covers coordination. Your thesis repackages basics like task decomposition as military wisdom. It’s common sense wrapped in camo.”
Then Grok war-gamed each publication approach: Self-publishing (Obsidian) is “ghettoized to note-taking nerds” with no SEO and tiny audience. Academic journals will reject interdisciplinary work — “rejection rates >80%.” Tech platforms will downvote military framing as problematic. LinkedIn will ignore non-corporate content.
Grok’s second-order effects analysis was brutally specific: If traction occurs, expect backlash on autonomous weapons ethics. If no traction, the 50K+ words drafted represent months lost. If a competitor publishes similar work first, yours looks derivative. If AI landscape shifts (AGI scenarios), the doctrine framework becomes quaint.
Grok’s contrarian recommendation: “Scrap the series — it’s unfocused bloat. Build a GitHub repo with CMDP code/simulations — let code do the talking, not essays.” This is deliberately harsh, but it surfaces a genuine strategic question: in a field of PhDs building real systems, do essays compete effectively?
The value of Grok’s analysis is not that it is correct — it is that these are the exact objections the author must anticipate and pre-empt in the papers themselves.
The ensemble value is not simply additive. During synthesis, the Commander (Claude) attends to each staff officer’s analytical outputs — not just reading them in sequence, but cross-referencing positions to identify where independent analyses reinforce or contradict each other. Gemini’s serialization recommendation and ChatGPT’s hybrid COA are independently derived; their convergence is signal, not consensus. Grok’s attack vectors cross-referenced against Gemini’s market analysis reveals a structural gap: the credibility vulnerabilities Grok identified are most exposed exactly where Gemini’s threat (the consultancy threat) is most active.
With all four voices captured — environmental intelligence, operational planning, and contrarian attack — the Commander’s synthesis phase begins: where do the models agree, and where do they diverge?
5. CONVERGENCE AND DIVERGENCE
Section titled “5. CONVERGENCE AND DIVERGENCE” Figure 4: Convergence/Divergence Analysis — Key findings at center where all models aligned, unique insights orbiting outward by source.
Figure 4: Convergence/Divergence Analysis — Key findings at center where all models aligned, unique insights orbiting outward by source.
Four independently trained models converging on the same recommendation is a bootstrap aggregation signal — the variance across models measures the stability of the recommendation. Where all four models agreed (lead with Paper 2, sequential release), the recommendation is stable regardless of which model’s training prior dominates. Where only one model raised an issue (Grok’s GitHub professionalization challenge), the finding requires further validation before acting.
Convergence under structured roles also suggests the team reached a Nash equilibrium on high-confidence findings — no model could unilaterally improve the outcome by changing its position. The recommendation to lead with Paper 2 is stable: Gemini cannot improve its position by switching to Paper 1 (which it flagged as not ready), and neither can any other model. Each model’s assigned-role analysis arrives at the same dominant strategy.
High-Confidence Findings (Where All Models Aligned)
Section titled “High-Confidence Findings (Where All Models Aligned)”-
Lead with Paper 2. Every model — solo Claude, Gemini, ChatGPT, even Grok’s attack — identified “The Digital Battle Staff” as the strongest asset. It is the most complete, rigorously edited, defensible piece. This is the flagship.
-
Obsidian Publish is the lab, not the storefront. Solo Claude called it “a portfolio, not a distribution channel.” Gemini said “Second Brain, not First Impression.” Grok called it “ghettoized to note-taking nerds.” Universal agreement: host deep content here, but discovery happens elsewhere.
-
Paper 1 is not ready for publication. Solo Claude flagged blockers (Research Notes removal, Footnote verification, Section sourcing). Grok called it “amateur” in draft state. ChatGPT excluded it from early sequencing in 2 of 3 COAs. Consensus: do not post anywhere until editorial fixes complete.
-
Sequential release beats data dump. Gemini’s “Serialization strategy,” ChatGPT’s phased timelines, solo Claude’s staggered weeks all converge: sequencing creates audience-building momentum.
-
The military angle is a differentiator, not a limiter. Gemini strongest here: “The Digital Battle Staff is the only viable metaphor for managing 100+ autonomous agents.” Even Grok, attacking military framing, acknowledged that “SOF + LSS + hands-on AI agent credentials” have no direct competitor.
Unique Ensemble Insights (What Ensemble Surfaced That Solo Missed)
Section titled “Unique Ensemble Insights (What Ensemble Surfaced That Solo Missed)”Delta findings are rated by the Commander during synthesis: HIGH = immediately actionable with direct strategic impact; MEDIUM-HIGH = actionable but requiring synthesis; MEDIUM = strategic insight requiring editorial integration. The yield on ensemble-only insights — findings that required no rework and were immediately actionable — was 2 of 6 (33%). The remaining four required synthesis before application.
Delta Finding 1: The Serialization Strategy (Gemini) — HIGH Value
Serialize Paper 2’s 33,500 words into 10 “Operational Briefs” for Substack/LinkedIn. Solo Claude treated Paper 2 as monolithic. Gemini saw a content asset generating 10 weeks of material. This insight is tactical and immediately actionable — it converts a single publication event into a sustained content campaign. This finding was actionable as-is; no synthesis required.
Delta Finding 2: The Hybrid COA (ChatGPT) — MEDIUM-HIGH Value
“Doctrine → Articles → Case Studies → Book.” ChatGPT synthesized multiple approaches into a hybrid generating more content touchpoints from the same material. Solo Claude’s recommendation added LinkedIn but did not envision short-form article serialization. Actionable but requiring integration with the serialization finding.
Delta Finding 3: The Consultancy Threat (Gemini) — MEDIUM Value
McKinsey/Deloitte rebranding LSS for AI creates a specific, named competitive threat with timeline urgency. Solo Claude treated competitor risk as generic. Gemini identified the precise threat vector and the urgency it creates — the window to be first with military doctrine applied to AI coordination is closing. Requires strategic editorial integration.
Delta Finding 4: The Credibility Attack Surface (Grok) — HIGH Value
Detailed, specific credibility vulnerabilities that solo Claude avoided:
- “No PhD, no affiliations with labs” — ad hominem risk
- “CMDP pilot lacks reproducibility, sample size, or controls” — methodological vulnerability
- “Papers vary wildly in quality” — coherence problem
- “‘Doctrine’ is just fancy for protocols” — uniqueness challenge
These are the objections the author must pre-empt in the papers themselves, not just in publication strategy. Immediately actionable: use these as editorial checkpoints.
Delta Finding 5: The “Professionalize or Shelve” Challenge (Grok) — MEDIUM Value
Build a GitHub repo with CMDP code/simulations. Solo Claude never considered moving beyond essays. Grok’s point — that in a field of PhDs building systems, essays compete on a weaker playing field — is a directional strategic challenge requiring further analysis.
Delta Finding 6: The DOW/SOCOM Alignment (Gemini) — MEDIUM Value
Position the series as the “Field Manual for the Agent Network” to align with Department of War’s 2026 initiatives. Solo Claude mentioned SOCOM and DARPA timelines but did not make the explicit positioning recommendation. Requires integration with broader communications strategy.
The ensemble value is not simply additive. During synthesis, the Commander (Claude) attends to each staff officer’s analytical outputs — cross-referencing positions to identify where independent analyses reinforce or contradict each other. Gemini’s serialization recommendation and ChatGPT’s hybrid COA are independently derived; their convergence is signal, not consensus. Grok’s attack vectors cross-referenced against Gemini’s market analysis reveals a structural gap: the credibility vulnerabilities Grok identified are most exposed exactly where Gemini’s threat (the consultancy threat) is most active.
With all four voices captured — environmental intelligence, operational planning, and contrarian attack — the Commander’s synthesis phase produces not a list of findings but a coherent decision foundation.
6. WHERE SOLO EXCELLED
Section titled “6. WHERE SOLO EXCELLED”The ensemble is not universally superior.
Operational Detail: Solo Claude produced week-by-week plans with hour estimates, named tools, decision gates, contingencies. Ensemble members produce strategic analyses requiring operational translation.
Risk Register: Solo Claude’s structured risk table with likelihood, impact, mitigations is more actionable than Grok’s attack vectors.
Time-Critical Constraints: Solo Claude uniquely factored DARPA and SOCOM deadlines as hard constraints shaping the timeline.
Assumption Validation: Solo Claude created actionable validation tasks with deadlines. Ensemble challenged abstractly without creating tasks.
The lesson: ensemble members think strategically; a solo decision-maker produces orders.
 Figure 5: Solo vs Ensemble Capability Comparison.
Figure 5: Solo vs Ensemble Capability Comparison.
7. REFINED THESIS
Section titled “7. REFINED THESIS”Original Hypothesis: “A structured multi-model ensemble outperforms an individual model applying the same framework.”
Refined After Proof-of-Concept: “A doctrine-structured multi-model ensemble exposes strategic gaps that solo analysis misses, while solo analysis produces superior operational execution detail. The optimal pattern is ensemble for strategy, solo for operations — and doctrine is the constant that makes both work.”
This maps directly to military organizational experience. The Commander’s staff (ensemble) develops options, identifies threats, challenges assumptions, and surfaces risks. The Commander (solo decision-maker) selects a course of action and produces the order. The staff process (doctrine/MDMP) is what makes both work. The staff without a commander produces briefings. The commander without a staff produces orders that overlook risks. Together, under doctrine, they produce sound decisions.
Without doctrine, the ensemble is four models talking past each other, each outputting analysis nobody synthesizes. With doctrine, each model’s unique training biases become complementary strengths rather than contradictory noise.
Claude brings training that emphasizes safety and balanced helpfulness. Gemini brings broad search capability and current-events awareness. ChatGPT brings operational planning experience. Grok brings aggressive truth-seeking and assumption challenging. Without structure, these differences produce incompatible outputs. With MDMP roles, these differences fill specific analytical gaps in coverage.
The MDMP is not the only possible doctrine for multi-model coordination. It is not even the best doctrine for all problems. But this proof-of-concept proves that doctrine — structure, role assignment, defined interfaces, and synthesis procedures — is the actual variable that determines whether multiple models cooperate or clash. This is the toboggan principle: gravity-fed channels that make the right decision the default decision, amplifying the strengths of each role. In practice the agent becomes more of a factory worker pushing the template around the work area — or, in this case, taking a ride on a reverse-entropy information enricher slide — than a free-wheeling analyst navigating every decision from scratch. Structure carries the load; the model supplies the judgment at each station. Paper 8 (“The Toboggan Doctrine”) explores how this principle extends to governance of agent lifecycles at scale.
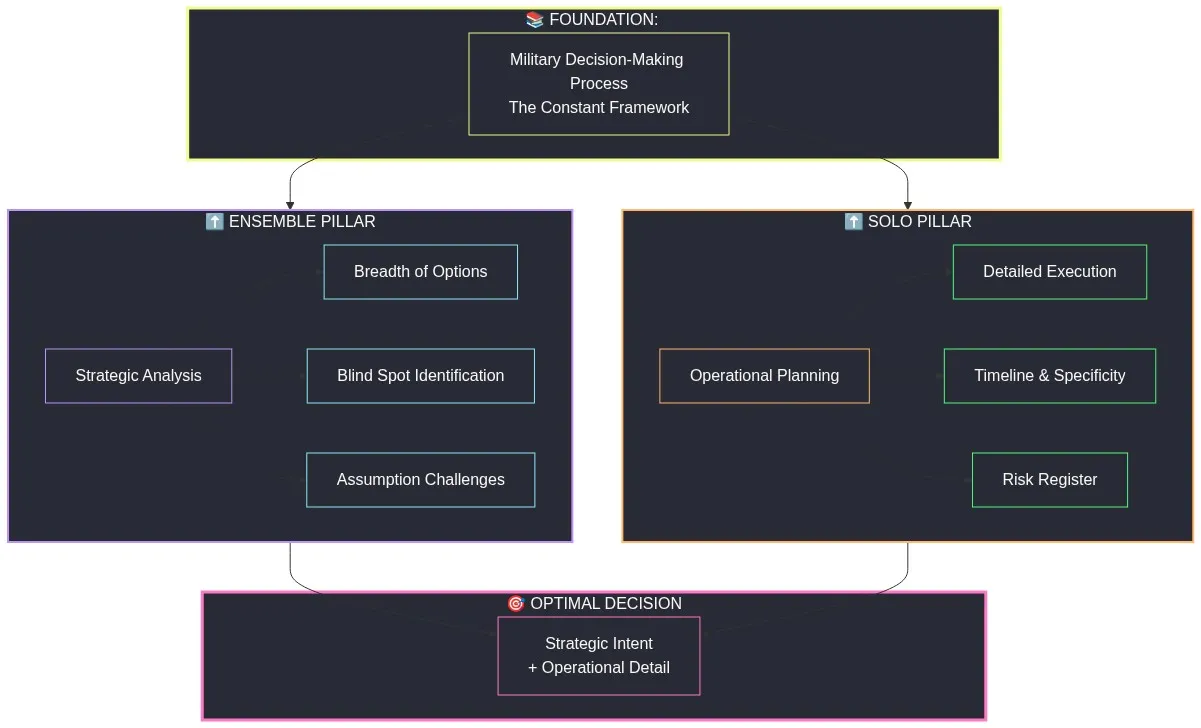 Figure 6: Refined Thesis Architecture — Doctrine (MDMP) as foundation, Ensemble pillar (strategic analysis) and Solo pillar (operational planning) supporting optimal decision.
Figure 6: Refined Thesis Architecture — Doctrine (MDMP) as foundation, Ensemble pillar (strategic analysis) and Solo pillar (operational planning) supporting optimal decision.
8. LIMITATIONS AND HONEST ASSESSMENT
Section titled “8. LIMITATIONS AND HONEST ASSESSMENT”The comparison in this paper is between ensemble coordination and a default solo baseline, not between ensemble and a maximally-prompted solo model. The solo baseline received a standard MDMP briefing. Some ensemble findings — the McKinsey/Deloitte threat, the GitHub professionalization challenge — could have been elicited from solo Claude with targeted domain questions (“What management consultancy threats exist in your competitive landscape?”). The proof-of-concept does not isolate whether ensemble value comes from multi-model diversity or from role-constraint prompting forcing coverage of specific analytical domains.
This does not invalidate the findings. In practice, knowing which domain questions to ask is itself the knowledge the ensemble structure provides. The S2 role tells you to conduct threat analysis even when you do not know to ask for it. But this paper must frame this honestly: the ensemble outperformed a standard solo baseline. Whether a more thoroughly prompted solo model would close the gap is a research question this proof-of-concept does not resolve.
The 2x time cost is real: ensemble required approximately 15 minutes; solo required approximately 8 minutes. For a single strategic decision affecting multiple publication platforms and high-stakes timelines, this is an acceptable tradeoff. For operational planning or time-critical response, the ensemble cost is prohibitive.
The proof-of-concept represents n=1 decision problem. Replication with different decision types — technical architecture choices, resource allocation conflicts, personnel decisions — is required before generalizing findings broadly.
The findings may be model-version-sensitive. This proof-of-concept used frontier models (Claude Opus 4.6, Gemini 3, GPT-4o, SuperGrok). Whether the same ensemble structure produces comparable results with less capable models — or whether the value comes from the structure rather than raw capability — is an open question. If the findings are structure-dependent, they generalize broadly. If capability-dependent, they apply only at the frontier.
Browser-mediated interaction introduces latency and format constraints not present in API-driven ensemble coordination. The actual performance of a doctrine-structured ensemble operating via direct machine-to-machine protocols remains unexplored.
CONCLUSION
Section titled “CONCLUSION”AI agents are cats. Different training produces different instincts, failure modes, blind spots, strengths.
Four cats without structure: chaos. Documented failure rate: 41-86.7% depending on coordination topology.
Four cats with structured roles and synthesis procedures: a team. The ensemble produced 6 strategic insights solo missed. The solo model produced superior operational detail. Combined: stronger than either alone.
The series arc: AI needs doctrine (Paper 1) because military has it (Paper 2), and it works (Paper 3), failures occur without it (Paper 4), two models can coordinate (Paper 5), four models can staff a decision (Paper 6).
The bridge to Paper 7: if four models can staff a decision via browser in 15 minutes, what happens with direct API coordination? What happens when synthesis is automated? What happens when decision-to-outcome feedback loops back into the ensemble?
Consider Paper 6’s most telling moment: Grok — trained to challenge everything — called the series “niche bloat” and recommended scrapping it. That is exactly what a good contrarian role should do. Without role assignment, it would be noise. With it, the attack became the paper’s best credibility test. Structure did not silence Grok. Structure aimed it.
The future is not “which AI model is smartest.” The future is “how do we coordinate multiple AI systems into an effective staff?”
The cats have learned to herd themselves — but only when given doctrine to follow.
 Figure 7: Series Arc.
Figure 7: Series Arc.
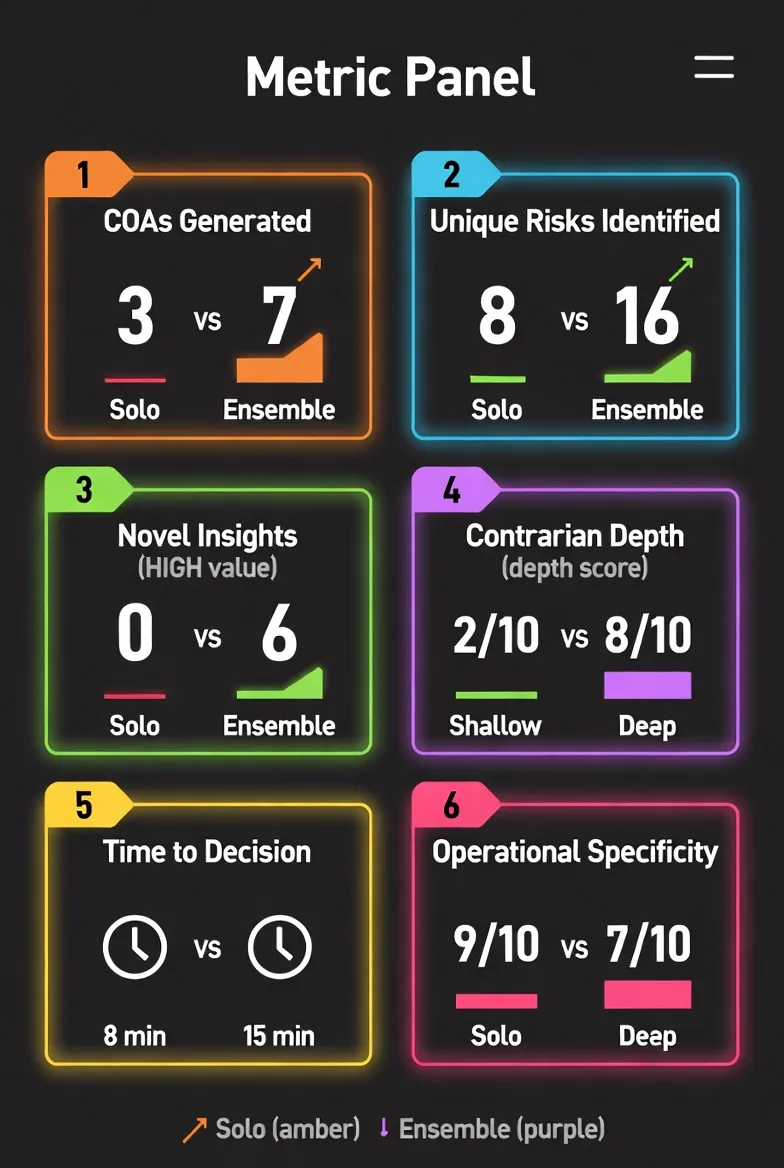 Figure 8: PoC Metrics Dashboard.
Figure 8: PoC Metrics Dashboard.
Appendix A: Comparative Model Outputs
Section titled “Appendix A: Comparative Model Outputs”The primary figures above show each concept rendered by the model that produced the strongest result for that scene. The same briefs were submitted to ChatGPT and Grok in parallel, and those variant renderings directly demonstrate the capability dispersion thesis of this paper — identical prompts, identical briefs, different training philosophies, different visual outputs. Additional variant renders from each model are retained in the source vault for interested readers.
FOOTNOTES
Section titled “FOOTNOTES”Canonical source: herding-cats.ai/papers/paper-6-cats-form-a-team/ · Series tag: HCAI-47d89c-P6
Series Navigation
Section titled “Series Navigation”| This paper | Paper 6 of 10 |
| Previous | ← Paper 5: When the Cats Talk to Each Other |
| Next | Paper 6b: When the Cats Take the Same Test → |
| Case Study | Case Study 1: Session Close Automation |
| Home | ← Series Home |
Related
Section titled “Related”- Herding Cats in the AI Age (series home)
- Paper 5: When the Cats Talk to Each Other
Footnotes
Section titled “Footnotes”-
UC Berkeley EECS-2025-164: “From Local Coordination to System-Level Strategies: Designing Reliable, Societal-Scale Multi-Agent Autonomy Across Scales,” Victoria Tuck, 2025. Identified failure modes with 41–86.7% failure rates depending on topology. https://www2.eecs.berkeley.edu/Pubs/TechRpts/2025/EECS-2025-164.html ↩
-
“Towards a Science of Scaling Agent Systems,” Yubin Kim, Ken Gu, et al. (Google Research, MIT, Google DeepMind), 2025. arXiv:2512.08296. Found multi-agent systems degrade sequential task performance by 39–70% while improving parallel task performance by 80.9%. https://arxiv.org/abs/2512.08296 ↩